iPhone 17 Air's ultra-thin design revealed early
The post iPhone 17 Air's ultra-thin design revealed early appeared first on Android Headlines....


The post iPhone 17 Air's ultra-thin design revealed early appeared first on Android Headlines....

The best budget gaming laptop offers solid performance with a balance of speed, graphics, and affordability. This articl...


If you’ve played any of the versions of Nintendo’s Animal Crossing over the years, you’ll know that eventually you...

The HMD Skyline, a mid-range smartphone developed by the company behind Nokia, introduces a refreshing perspective to mo...
Fiscal year 2024 revenue of $944M, up 19% YoY Q4 revenue growth of 18% year-over-year Q4 net income of $19.1 million and...
BARCELONA, Spain, Feb. 18, 2025 /PRNewswire/ -- Freightos (Nasdaq: CRGO), the world's leading digital freight booking an...

DALLAS, Feb. 18, 2025 /PRNewswire/ -- Tune in to upcoming fireside chats with John Stankey and Pascal Desroches that wil...
New Strategic Partnership Enhances Customer Experience with GenAI-Powered Roleplaying for GTM Enablement, Leadership Dev...
ANN ARBOR, Mich., Feb. 18, 2025 /PRNewswire/ -- With 70% of traditional district strategic plans failing in implementati...

There’s a bar, a Yankee salesman, a head cook named Pearl who stayed on for decades. There’s a woman who threw her p...
Mobisoft, acquired by Sky Camp Ventures, is now MiO DENVER, Feb. 18, 2025 /PRNewswire/ -- Sky Camp Ventures, a subsidiar...

Sometimes, the tools we rely on every day can feel like an afterthought—functional but uninspired, practical but lacki...

Drivers have been advised to do one thing straight after an accident in order to avoid complications with their insuranc...

Apple's February 19 event will likely feature the new iPhone SE, MacBook Air updates, iPads, and more exciting products....
VAN BUREN TOWNSHIP, Mich., Feb. 18, 2025 /PRNewswire/ -- Visteon Corporation (NASDAQ: VC) today reported fourth quarter ...


This growth is fueled by a combination of government initiatives like the production-linked incentive (PLI) schemes and ...

Overhaul will address "many longstanding concerns and frustrations"....

Consider Brendan Carr unimpressed. The FCC chair responded to Sheryl Crow's Tesla move—the singer sold off her EV and ...

The iPhone 17 lineup will include an ultra-thin model, the first of its kind. Dubbed the iPhone 17 Air, the device seems...

The Nothing Phone 3a camera design has been revealed ahead of its launch on March 4, 2025. Know what to expect....

The iPhone 17 Air is expected to be the thinnest model yet at 5.5mm, with a new horizontal camera design. Apple may tran...

Tadej Pogačar loses vital teammate after stage 1 crash...

Kamayani Express and Dadar Express halted for search operations after social media bomb threat in Uttar Pradesh...

Leaker Evan Blass has revealed a lot of what Lenovo has planned for MWC 2025 — with the headline reveal being a new ki...

The shares of Super Micro Computer Inc. (NASDAQ:SMCI) rose 4.8% during the pre-market trading session on Tuesday amid po...

Over half (52.71 per cent) of the funds for core projects of the Smart City Mission were spent revamping failing transpo...

If successful, it’d have made the merger the third largest automaker in the world behind Toyota and VW GroupIn what is...

CNBC's Phil LeBeau joins 'Squawk Box' to report on the latest news....

Apple will bring its new M5 chip to the MacBook Pro before the iPad Pro, according to a new report....

In recognition of American Heart Month, the American Heart Association, devoted to a world of healthier lives for all, a...

Meetings are a cornerstone of teamwork, but let’s be honest—keeping track of meeting notes can feel like an uphill b...

Sylvia Jablonski, Defiance ETFs CEO and CIO, joins 'Squawk Box' to discuss the latest market trends, where investors can...

Mexican President Claudia Sheinbaum announced that Mexico would take legal action against Google for renaming the Gulf o...

CNBC’s Brandon Gomez joins 'Squawk Box' to break down CNBC/SurveyMonkey's latest small business confidence survey for ...

We've got more tri-fold news: for Samsung's rumored device, and Huawei's existing handset....

South Korea's data protection regulator says user data was sent to the Chinese owner of TikTok....

Looking for top-tier gaming phones? Here are a few options that won’t miss a beat....

Briton wins, takes red jersey as Stefan Bissegger and Tadej Pogačar round out podium...

Prime Video’s romantic drama is my new guilty pleasure movie, and it might surprise you. Here’s everything to know a...

Looking for the best Xiaomi smartphones under ₹15,000? Explore our list of top budget-friendly Xiaomi models featuring...

The Ratio Four is a truly simple single-serve drip coffee machine that makes barista-caliber coffee....

The post Here’s the difference between Nothing Phone (3a) and its Pro counterpart appeared first on Android Headlines....

Samsung has officially released a significant software update for its Galaxy smartphone lineup, including flagship model...

Even as venture capital funding for the industry continued to fall in 2024, many fintechs–especially those serving oth...

Regional and community financial institutions (RCFIs) have a unique opportunity to differentiate themselves from major n...

Presidents' Day sales are taking off $700 on some of the best gaming laptops, including RTX 4090-equipped PCs....

From processing giant Stripe to DailyPay, which helps hourly workers get their money faster, 11 payment companies made o...

Astrology and numerology suggest certain birth dates should avoid alcohol due to emotional and impulsive tendencies. Tho...

Eight personal finance fintechs made the list this year, as startups moved beyond digital banks to creative niche soluti...

The 18 companies making their debut on our tenth annual Fintech 50 list show that despite a slow funding market, entrepr...

Learn why tin is becoming increasingly valuable and what the future holds for this critical metal....

Huawei has recently launched its roadshows for the ‘Seeds For The Future Bangladesh’, an initiative designed to enha...

PURE EV riders will get access to the Jio Automotive App Suite (JAAS)—a hub for JioStore, music streaming, web browsin...

Coming soon, a "next generation search engine" powered by Grok.Elon Musk took time away from infiltrating the White Hous...
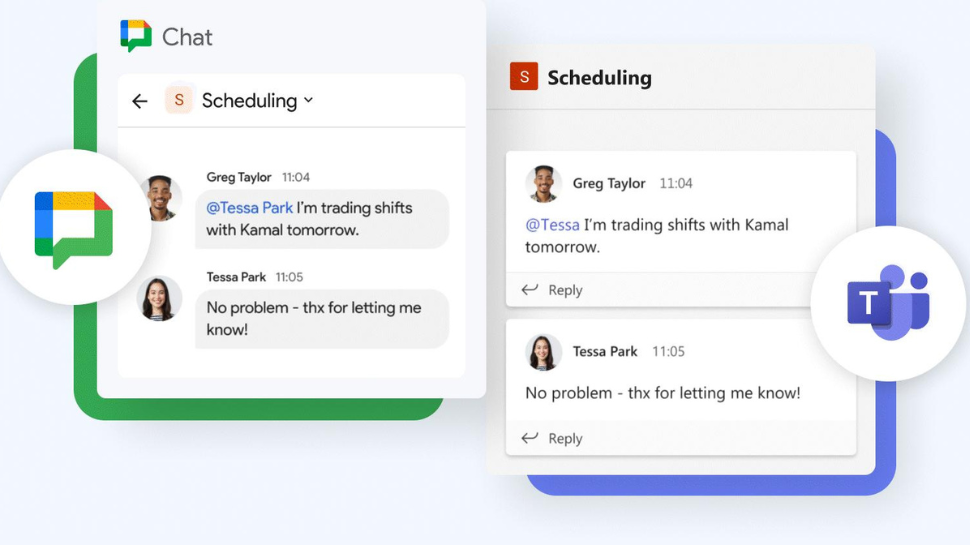
Users can now migrate messages from Microsoft Teams to Google Chat with new service....

Is this what the iPhone 17 Pro model looks like in Apple's upcoming iPhone 17 series? Front Page Tech's 3D artist Asher ...

Improve your performance and prevent injuries with the best running shoes of 2025....

Samsung Galaxy A26 5G has recently started doing rounds of the rumour mill. Leaked CAD renders and some expected feature...

